
Machine learning (ML) is an application of artificial intelligence (AI), used in everything from self-driving cars to marketing software. Forward-minded companies are increasingly using ML to innovate, improve processes, increase efficiency, and more.
Automating certain tasks and processes can help a company streamline operations and get ahead. Decision makers need to understand machine learning and how it works so they can incorporate it into their business and achieve the automation necessary to be successful.
In this guide:
What is machine learning?
Machine learning is a component of artificial intelligence that gives machines the ability to learn automatically from past experiences and data while noting patterns to create predictions with little to no human intervention. Using the data it processes, machine learning software imitates how humans learn and becomes more accurate over time.
Machine learning is the technology behind chatbots, language translation apps, show and movie suggestions in streaming services, and the posts that show up on your social media feed. It gives computers the ability to acquire knowledge without specifically being programmed to know certain pieces of information. It can improve personal and professional functions in our everyday lives.
Machine learning offers some significant benefits. It can take in and process huge amounts of data — far beyond human capabilities — and quickly learn from that information. Machine learning can differentiate objects and recognize faces, giving us the facial recognition technology many people have on their smartphones. It can quickly compare data and provide a variety of options and solutions that would take a human much more time.
Machine learning is also a key component of marketing. For example, it can allow social media platforms to target advertisements to every individual’s feed. Machine learning extends communication abilities and creates more personalized experiences for consumers. Helplines and chatbots are also made possible because of machine learning, enabling companies to assist more customers than they would if they only relied on a human workforce.
Machine learning (ML) vs. deep learning (DL) vs. neural networks.
While machine learning and neural networks are often used interchangeably, they are not the same. Neural networks are a subfield of machine learning, and deep learning is a subfield of neural networks.
Artificial neural networks are modeled on the human brain, with thousands or millions of processing nodes that are interconnected and organized into layers. Neural networks comprise three node layers — an input layer, one or more hidden layers, and an output layer.
Each node connects with another and has its own weight and threshold. If the output of a node is higher than its specific threshold value, that node will activate and share data with the next layer in the network. Apart from that, no data passes to the next network layer from that node.
Also modeled on the way the human brain works, deep learning networks are neural networks with many layers. According to the MIT Sloan School of Management, “The layered network can process extensive amounts of data and determine the ‘weight’ of each link in the network.”
Deep learning can use labeled datasets to guide its algorithm, but it doesn’t necessarily need them. Deep learning takes in raw data, such as images or text and automatically recognizes certain features that will separate different sets of data from one another. The need for human involvement is less frequent, and it can handle larger datasets compared to traditional (non-deep) machine learning, which is more dependent on human intervention.
AI vs. machine learning (ML) vs. deep learning (DL).
Understanding the subtle but significant differences between artificial intelligence, machine learning, and deep learning (DL) is essential to implementing these technologies effectively. Choosing the right approach depends on the business problem, available data, resources, and strategic goals.
The relationship between these concepts is often visualized as a hierarchy. Artificial intelligence (AI) is the broadest category, covering all technologies that enable machines to simulate human intelligence. Machine learning (ML) is a subset of AI that focuses on algorithms that learn from data and improve over time without being explicitly programmed. Deep learning (DL) is a further subset of ML that uses highly complex neural networks with multiple layers to solve more sophisticated problems.
Think of it like this:
AI includes ML, and ML includes DL.
What is deep learning?
Deep learning is a type of machine learning that uses deep neural networks—networks with multiple hidden layers between the input and output. While simple (or “shallow”) neural networks might handle basic prediction tasks, deep learning models are capable of analyzing massive datasets and uncovering complex patterns that simpler models cannot.
This depth allows deep learning models to power highly advanced technologies like voice assistants, real-time language translation, fraud detection, and autonomous vehicles.
In short:
- All deep learning uses neural networks.
- But not all neural networks are “deep” enough to qualify as deep learning.
What is artificial intelligence?
Artificial intelligence (AI) is how machines simulate human intelligence, usually to perform advanced tasks without human intervention. With AI, machines perform tasks that are commonly associated with intelligent beings.
In practice, AI is human-made thinking power performed by machines. Virtual assistants like Siri and Alexa use AI to learn your preferences and suggest relevant results. AI-powered chatbots also allow shoppers to get personalized support outside of normal business operating hours.
It’s also important to remember that there are several types of AI. Organizations use one or several types of AI to accomplish different tasks.
The table below shows the key differences between AI, machine learning, and deep learning.
How machine learning works.
Machine learning essentially uses algorithms to create more accurate predictions. These algorithms can be:
- Descriptive — using data to interpret what occurred
- Predictive — using data to foresee what will take place
- Prescriptive — using data to suggest actions to take
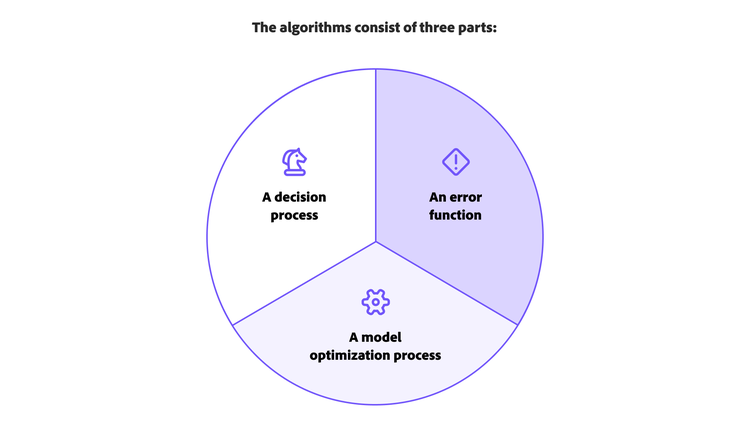
The algorithms consist of three parts:
- A decision process. For the most part, machine learning algorithms are used to guess and organize incoming information. Based on the provided data, the algorithm will create a prediction about a pattern within it.
- An error function. This part of the algorithm assesses the model’s prediction. If there are examples that have already been investigated, an error function can create a comparison to evaluate the accuracy of the model.
- A model optimization process. If the model can adjust more easily to the data points in the training set, weights will adjust to decrease any discrepancy between the investigated example and the model’s prediction. This process repeats by the algorithm, which updates weights until the threshold of accuracy has been reached.
There are different ways that these algorithms can be taught how to use data. Let’s look at the four main approaches to machine learning.
Supervised learning.
Using labeled datasets to train algorithms, this subcategory of machine learning follows instructions based on the information it is given.
Machines are taught information from labeled datasets and authorized to guess outputs based on the provided instructions. The labeled dataset identifies input and output parameters that are already depicted, and the machine is taught with the input and corresponding output.
Supervised learning is further divided into two broad categories:
- Classification. These algorithms respond to classification issues where the output component is categorical. Some examples of this are “yes or no” or “true or false.” An example of classification used in daily life is the filtering capabilities in email applications — choosing primary email box messages versus spam box messages. Some recognized classification algorithms include the logistic regression algorithm, support vector machine algorithm, and random forest algorithm.
- Regression. These algorithms manage regression issues where input and output components have a linear relationship. They foresee what the continuous output components will be. Examples of this would include a market trend analysis or a weather forecast. Some known regression algorithms include simple linear regression, lasso regression, and multivariate regression.
Unsupervised learning.
Unsupervised learning is used to analyze and cluster unlabeled datasets to find patterns without the need for human intervention.
An unsupervised machine learning program will search for unlabeled data and find patterns that people aren’t looking for specifically. For example, an unsupervised machine learning program can identify primary client bases for an online store. Some known unsupervised learning approaches include nearest-neighbor mapping and self-organizing maps.
The advantage of unsupervised learning is its ability to find similarities and differences between groupings without human intervention. This algorithm can group unsorted datasets by patterns, differences, and similarities.
Unsupervised learning has a couple of sub-classifications as well:
- Clustering. This approach groups objects into clusters based on guidelines such as differences or similarities between them. An example of this is organizing customers by the items they purchase.
- Association. This technique identifies standard relations between the variables in a large dataset. It decides the dependency of data items — and charts the associated variables.
Semi-supervised learning.
As its name suggests, this approach merges aspects of supervised and unsupervised machine learning.
Semi-supervised learning reads labeled and unlabeled datasets to teach its algorithms. Combining both datasets eliminates the problems that come with using each of them on its own. In addition, the semi-supervised learning approach uses smaller labeled datasets to guide and manage larger unlabeled datasets. The datasets are usually grouped this way because unlabeled data requires less effort and is less expensive to acquire.
Think about a student learning from a teacher. If a student receives information from a teacher, that would be considered supervised learning. When studying independently at home, the student is learning the information without supervision from the teacher. But if the student reviews the information with a teacher in class after learning it, this would be analogous to semi-supervised learning.
An example of semi-supervised machine learning in daily life would be a webcam that identifies faces.
Reinforcement learning.
Reinforcement learning trains through reward systems. It uses trial and error to learn as it goes, with successful outcomes reinforcing recommendations. Reinforcement learning doesn’t have labeled data like the supervised learning technique. This type of machine learning works on a feedback process of actions and learns through experiences.
Reinforcement learning takes the most appropriate action by learning from experiences and adjusting its actions accordingly. There are rewards for correct actions taken and penalties for wrong ones. This helps the system learn the correct actions to take.
Reinforcement learning is popular in video games, robotics, and navigation. In video games, for example, the game defines the environment, and every movement made by the reinforcement learning agent determines the agent’s current state. The agent will receive feedback through rewards and penalizations, which affect the game score.
There are two types of reinforcement learning algorithms:
- Positive reinforcement learning. This type of reinforcement learning involves the addition of a reinforcing aspect after a certain behavior is performed by the agent, making it more likely that the behavior will occur again in the future.
- Negative reinforcement learning. This type of reinforcement involves the removal of a negative condition to increase the chances of a particular behavior occurring again, or the strengthening of a particular behavior that will avoid a negative result.
Machine learning uses.
Many industries that work with large volumes of data see the value in using machine learning technology to boost productivity. Machine learning is not a replacement for humans but rather a tool that helps to extract information quickly and accurately so that humans can evaluate the recommended actions and make better, faster decisions.
Let’s look at some of the industries that most commonly use machine learning.
Healthcare.
Machine learning is quickly expanding across the healthcare field. Wearable sensors and devices like smart watches or fitness trackers can help medical experts gain real-time insight into a patient’s health. A few benefits of machine learning in healthcare include:
- Analyzing data more quickly and efficiently. With the data presented and analyzed in real time, health red flags or patterns can be spotted easily to provide updated diagnoses or treatments more quickly.
- Assessing patient health in real time for more personalized care. While drugs can treat symptoms, individual patients’ side effects may be different. Machine learning can study an individual’s genes to provide personalized care and targeted treatment for each patient.
- Faster drug discovery. Machine learning can speed up the long and expensive process of creating a new drug. Some machine learning tools can analyze large datasets to help discover new potential drug treatment options.
Finance.
Banks and other financial institutions handle large amounts of sensitive information. Many companies have chosen to use machine learning technologies to provide a more secure and efficient service for their customers. Among the benefits of machine learning in finance are:
- New insights into data. New investment opportunities can be discovered quickly, and better insights can be provided to investors — for example, knowing the right time to trade.
- Better fraud protection. Security is crucial when managing financial information. Data mining spots users with high-risk profiles and helps cyber surveillance systems identify potentially fraudulent activities.
Retail.
The retail industry uses machine learning technology to create different experiences for each individual and provide additional customer assistance. Machine learning offers retailers the potential to expand their client base while cutting costs. A couple of key benefits are:
- Personalized shopping experiences. Many online retail sites use machine learning to offer suggestions for products based on recent purchases or bookmarks. Chatbots on a retail website can help answer a customer’s immediate questions, freeing up human representatives.
- Improved marketing. Machine learning can be a helpful tool for planning customer merchandise, putting together advertising campaigns, optimizing prices, and providing customer insights.
Machine learning algorithms.
Machine learning can be used to create recommendation engines and algorithms to personalize products and services for individuals.
Companies like YouTube and Netflix depend on machine learning algorithms to recommend movies and shows to viewers based on their watch history. Retail and other websites can suggest products and services based on saved or purchased items. In addition, social media platforms use machine learning to make recommendations, with different posts showing up on each person’s feed based on posts they have liked or accounts they follow.
Personalizing user experiences and gaining additional insights help organizations to better assist their customers. However, machine learning technology comes with its own challenges too.
Challenges for machine learning.
While machine learning has increased efficiency for many businesses in many industries, just like any other new technology, it has some drawbacks. In particular, there are ethical and cost concerns surrounding machine learning technology.
-
Bias and discrimination.
Unfortunately, the data used to train machine learning processes has the potential to reflect human bias. Algorithms that learn from datasets that have errors or exclude certain populations create inaccurate representations of the world. These errors fail to capture an accurate model of the world and can also be discriminatory. While most companies do their due diligence to eliminate potential bias in automation efforts, some consequences could emerge from using artificial intelligence.
For example, Amazon used automation to simplify hiring and unintentionally discriminated against candidates for technical positions based on gender. The company then did away with the process. Seeking input and data from people of different backgrounds can reduce bias and discrimination.
-
Privacy.
Machine learning requires data, and with that comes concerns around privacy. When managing all types of data — especially personally identifiable information (PII) — data privacy and security are of utmost importance. More and more lawmakers around the world are taking action to protect personal data.
The General Data Protection Regulation (GDPR) is a European Union law established in 2016 to safeguard the personal data of people in the European Union and European Economic Area and ensure individuals had more control over their information. In the United States, California passed the California Consumer Privacy Act (CCPA) in 2018 to mandate that businesses notify consumers when their data is collected.
-
Cost.
Implementing machine learning technology into business functions can be costly. Data scientists — the people usually driving these projects — often require high salaries. And the software infrastructure that comes with establishing machine learning practices can also be expensive.
Machine learning is implemented to search through large datasets created over time, and many resources are required to make the technology a useful part of business strategy. The time and resources expended are well worth the benefits for many businesses, but it’s important to remember that machine learning is an investment — and the system can become more complex and costly as it grows.
Power incredible customer experiences with machine learning.
Need improved segmentation and personalization with machine learning? Learn how Adobe Real-Time CDP can help.
Recommended for you
https://business.adobe.com/fragments/resources/cards/thank-you-collections/rtcdp
