
Le machine learning (ML) est une application de l’intelligence artificielle (IA), utilisée dans des domaines aussi variés que les voitures autonomes et les logiciels marketing. Les entreprises résolument tournées vers l’avenir font de plus en plus appel au ML pour, entre autres, innover, améliorer leurs processus et gagner en efficacité.
L’automatisation de certaines tâches et de certains processus peut aider une entreprise à rationaliser ses opérations et à garder une longueur d’avance sur la concurrence. Les décisionnaires doivent comprendre le machine learning et son fonctionnement afin de pouvoir l’intégrer dans leur entreprise et atteindre le niveau d’automatisation requis pour booster leur activité.
Voici les points abordés dans cet article :
- Définition du machine learning
- Machine learning vs. deep learning vs. réseaux de neurones
- Fonctionnement du machine learning
- Applications du machine learning
- Défis du machine learning
- IA vs. machine learning (ML) vs. deep learning (DL)
- Proposez des expériences client exceptionnelles avec le machine learning.
Définition du machine learning
Le machine learning est une composante de l'intelligence artificielle qui donne aux machines la capacité d’apprendre automatiquement à partir d'expériences et de données passées. Le programme est capable d’identifier des motifs et de faire des prédictions avec peu ou pas d’intervention humaine. En utilisant les données qu'il traite, le logiciel de machine learning imite la façon dont les humains apprennent et gagne en précision au fil du temps.
Le machine learning est la technologie derrière les chatbots, les applis de traduction linguistique, les suggestions de séries et de films dans les services de streaming, ainsi que les publications qui apparaissent sur votre fil d’actualité sur les réseaux sociaux. Il permet aux ordinateurs d'acquérir des connaissances sans être explicitement programmés pour connaître certaines informations. Il peut vous aider au quotidien dans vos tâches personnelles et professionnelles.
Le machine learning revêt des avantages importants. Il peut assimiler et traiter de gigantesques quantités de données, bien au-delà des capacités humaines, et en tirer rapidement des enseignements. Le machine learning peut différencier des objets et reconnaître des visages. Il est ainsi à l’origine de la technologie de reconnaissance faciale que beaucoup de gens ont sur leur smartphone. Il permet de comparer rapidement les données et de proposer diverses options ou solutions, ce qui demanderait beaucoup plus de temps à un être humain.
Le machine learning est également une composante clé du marketing. Il peut, par exemple, permettre aux plateformes de réseaux sociaux de proposer des publicités ciblées sur le fil de chaque internaute. Le machine learning décuple les capacités de communication et crée des expériences plus personnalisées pour la clientèle.Il est à l’origine des services d’assistance et des robots, grâce auxquels les entreprises aident un plus grand nombre de clientes et de clients qu’elles ne le pourraient si elles ne comptaient que sur leur personnel humain.
Apprentissage automatique (ML) vs deep learning (DL) vs réseaux de neurones
Le machine learning et les réseaux de neurones sont souvent utilisés de manière interchangeable. Pourtant, ils comportent des différences. Les réseaux de neurones sont un sous-domaine du machine learning, et le deep learning est un sous-domaine des réseaux de neurones.
Les réseaux de neurones artificiels sont modélisés sur le cerveau humain, avec des milliers ou des millions de nœuds de traitement interconnectés et organisés en couches. Ils sont composés de trois couches de nœuds : une couche d'entrée, une ou plusieurs couches masquées, et une couche de sortie.
Chaque nœud est relié à d’autres et possède un poids et un seuil propres. Si la sortie d’un nœud dépasse son seuil spécifique, ce nœud s’activera et transmettra des données à la couche suivante du réseau. En dehors de cela, aucune donnée n'est transmise à la couche suivante du réseau depuis ce nœud.
Également calqués sur le fonctionnement du cerveau humain, les réseaux de deep learning sont des réseaux neuronaux comportant de nombreuses couches. D’après la Sloan School of Management du MIT, « le réseau multicouche peut traiter d’importantes quantités de données et déterminer le poids de chaque lien dans le réseau ».
Le deep learning peut utiliser des jeux de données étiquetés pour guider son algorithme, mais il n’en a pas nécessairement besoin. Il prend en charge des données brutes, telles que des images ou du texte, et reconnaît automatiquement certaines caractéristiques qui permettront de distinguer différents ensembles de données les uns des autres. Le recours à une intervention humaine est moins fréquent, et il peut traiter des jeux de données plus volumineux que le machine learning traditionnel, qui dépend davantage de l’intervention humaine.
IA vs. machine learning (ML) vs. deep learning (DL)
Comprendre les différences subtiles mais importantes entre l’intelligence artificielle, le machine learning et le deep learning (DL) est essentiel pour mettre en œuvre efficacement ces technologies. Le choix de l'approche appropriée dépend du problème métier, des données disponibles, des ressources et des objectifs stratégiques.
La relation entre ces concepts est souvent représentée de manière hiérarchique. L’intelligence artificielle (IA) est la catégorie la plus large, couvrant toutes les technologies permettant aux machines de simuler l’intelligence humaine. Le machine learning (ML) est un sous-ensemble de l'intelligence artificielle (IA) qui se concentre sur des algorithmes capables d'apprendre à partir de données et de s'améliorer au fil du temps sans être explicitement programmés. Le deep learning (DL) est un sous-ensemble du ML qui utilise des réseaux de neurones très complexes à plusieurs couches pour résoudre des problèmes plus difficiles.
Pour résumer :
l’IA inclut le ML, et le ML inclut le DL.
Définition du deep learning
Le deep learning est un type de machine learning qui utilise des réseaux de neurones profonds, c’est-à-dire comportant plusieurs couches masquées entre l'entrée et la sortie. Si des réseaux de neurones simples (ou « peu profonds ») peuvent gérer des tâches prédictives élémentaires, les modèles de deep learning sont capables d’analyser d’immenses jeux de données et de mettre au jour des motifs complexes que les modèles plus simples ne détectent pas.
Grâce à cet apprentissage en profondeur, les modèles de deep learning alimentent des technologies très avancées, comme les assistants vocaux, la traduction linguistique en temps réel, la détection des fraudes et les véhicules autonomes.
En bref :
- Tout programme de deep learning utilise des réseaux de neurones.
- Mais tous les réseaux de neurones ne sont pas assez « profonds » pour être qualifiés de deep learning.
Définition de l’intelligence artificielle
L’intelligence artificielle (IA) désigne la manière dont des machines simulent l’intelligence humaine, généralement pour accomplir des tâches complexes sans intervention humaine. Avec l’IA, les machines accomplissent des tâches qui sont habituellement associées aux êtres intelligents.
En pratique, l’IA est une capacité intellectuelle créée par l’homme et mise en œuvre par des machines. Les assistants virtuels comme Siri et Alexa utilisent l’IA pour connaître vos préférences et suggérer des résultats pertinents. Les chatbots optimisés par l’IA permettent également à la clientèle de bénéficier d’une assistance personnalisée en dehors des heures ouvrables normales.
Il est également important de garder à l’esprit qu’il existe plusieurs types d’IA. Les entreprises utilisent un ou plusieurs types d’IA pour accomplir différentes tâches.
Le tableau ci-dessous présente les principales différences entre l’IA, le machine learning et le deep learning.
Fonctionnement du machine learning
Le machine learning utilise essentiellement des algorithmes pour créer des prévisions plus précises. Ces algorithmes peuvent être :
- Descriptifs : utilisation de données pour interpréter ce qui s'est passé
- Prédictifs : utilisation des données pour prévoir les évènements
- Prescriptifs : utilisation des données pour suggérer des actions à entreprendre
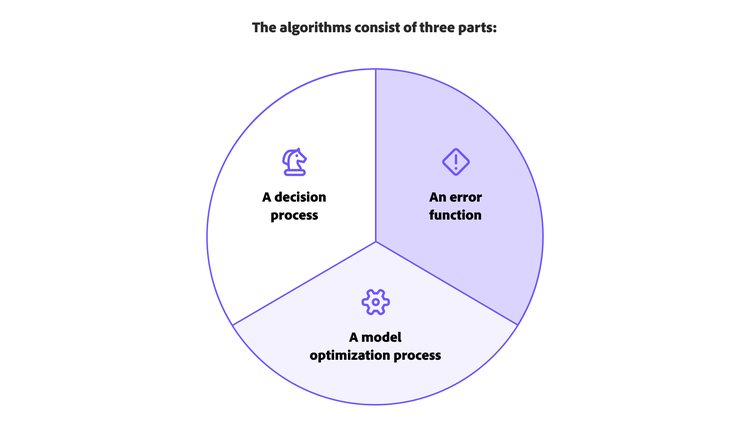
Les algorithmes se composent de trois parties :
- Processus décisionnel. La plupart du temps, les algorithmes de machine learning sont utilisés pour deviner et organiser des données entrantes. À partir des données fournies, l’algorithme va créer une prédiction concernant un motif présent dans celles-ci.
- Fonction d'erreur. Cette partie de l’algorithme évalue la prédiction du modèle. Si des exemples ont déjà été analysés, une fonction d’erreur peut établir une comparaison afin d’évaluer la précision du modèle.
- Processus d’optimisation du modèle. Si le modèle peut s’ajuster plus facilement aux points de données de l’ensemble d’entraînement, les poids seront ajustés afin de réduire tout écart entre l’exemple étudié et la prédiction du modèle. Ce processus est réitéré par l’algorithme, qui met à jour les poids jusqu’à ce que le seuil de précision soit franchi.
Il existe différentes façons d'enseigner à ces algorithmes comment utiliser les données. Voyons les quatre principales approches du machine learning.
Apprentissage supervisé
Cette sous-catégorie du machine learning utilise des jeux de données étiquetés pour entraîner les algorithmes et suit des instructions basées sur les données qui lui sont fournies.
Les machines sont autorisées à deviner les résultats en fonction des instructions fournies. Le jeu de données étiqueté identifie les paramètres d'entrée et de sortie déjà définis, et la machine est entraînée à partir des entrées et des sorties correspondantes.
L’apprentissage supervisé se divise lui-même en deux grandes catégories :
- Classification. Ces algorithmes répondent aux problèmes de classification lorsque la composante de sortie est catégorique. Par exemple, « oui ou non » ou « vrai ou faux ». Un exemple de classification utilisé au quotidien est la fonctionnalité de filtrage dans les applications de messagerie électronique, c’est-à-dire choisir les messages destinés à la boîte de réception principale ou ceux classés comme spam. Parmi les algorithmes de classification reconnus figurent la régression logistique, les machine à vecteurs de support (SVM) et les forêts aléatoires.
- Régression. Ces algorithmes gèrent les problèmes de régression où les variables d'entrée et de sortie ont une relation linéaire. Ils prédisent quelles seront les valeurs continues des variables de sortie. On peut citer comme exemple une analyse des tendances du marché ou des prévisions météorologiques. Parmi les algorithmes de régression connus figurent la régression linéaire simple, la régression Lasso et la régression multivariée.
Apprentissage non supervisé
L'apprentissage non supervisé est utilisé pour analyser et regrouper des jeux de données non étiquetés afin de déceler des motifs sans intervention humaine.
Un programme de machine learning non supervisé va rechercher des données non étiquetées et identifier des motifs qui ne sont pas spécifiquement recherchés. Par exemple, un programme de machine learning non supervisé peut identifier les principaux segments de clientèle d'une boutique internet. Parmi les approches connues d’apprentissage non supervisé figurent la méthode du plus proche voisin et les cartes auto-organisées.
L’avantage de l’apprentissage non supervisé est sa capacité à dégager des similitudes et des différences entre des groupes de données, sans intervention humaine. Cet algorithme peut regrouper des jeux de données non triés en fonction des motifs, des différences et des similitudes.
L'apprentissage non supervisé comporte quelques sous-classifications.
- Clustering. Cette approche regroupe les objets selon des critères tels que leurs différences ou leurs similarités. Par exemple, la clientèle peut être regroupée selon les produits qu'elle achète.
- Association. Cette technique identifie les relations standard entre des variables dans un vaste jeu de données. Elle détermine la dépendance des éléments de données et représente graphiquement les variables associées.
Apprentissage semi-supervisé
Comme son nom l’indique, cette approche fusionne les aspects du machine learning supervisé et non supervisé.
L’apprentissage semi-supervisé utilise des jeux de données étiquetés et non étiquetés pour entraîner ses algorithmes. La combinaison de ces deux jeux de données élimine les problèmes liés à l’utilisation de chacun d’eux séparément. De plus, l’approche d’apprentissage semi-supervisé utilise de petits jeux de données étiquetés pour guider et gérer de vastes jeux de données non étiquetés. Les jeux de données sont généralement regroupés de cette manière parce que les données non étiquetées demandent moins d’efforts et sont moins coûteuses à acquérir.
Songez à la relation d’apprentissage des élèves avec leurs profs. Si les élèves reçoivent des informations de leurs profs, cela peut être considéré comme un apprentissage supervisé. En étudiant de manière autonome à la maison, les élèves apprennent sans la supervision des profs. Mais si les élèves revoient les leçons apprises précédemment avec leurs profs en classe, cela peut correspondre à un apprentissage semi-supervisé.
Dans la vie quotidienne, une webcam qui identifie les visages est un bon exemple de machine learning semi-supervisé.
Apprentissage par renforcement
L'apprentissage par renforcement s’appuie sur des systèmes de récompense. Il apprend par tâtonnements au fur et à mesure, les résultats positifs renforçant ses recommandations. L’apprentissage par renforcement ne s’appuie sur aucune données étiquetées, contrairement à la technique d’apprentissage supervisé. Ce type de machine learning fonctionne selon un processus de boucles de rétroaction et apprend par l’expérience,
ce qui lui permet de prendre les mesures les plus appropriées en adaptant ses actions en conséquence. Des récompenses sont attribuées pour les actions correctes effectuées et des pénalités pour les actions incorrectes. Ainsi, le système apprend quelles actions correctes entreprendre.
L’apprentissage par renforcement est couramment utilisé dans les jeux vidéo, la robotique et la navigation. Dans les jeux vidéo, par exemple, le jeu définit l’environnement, et chaque mouvement effectué par l’agent d’apprentissage par renforcement détermine l’état actuel de l’agent. L’agent reçoit du feedback sous forme de récompenses et de pénalités, ce qui a une incidence sur le score du jeu.
Il existe deux types d'algorithmes d'apprentissage par renforcement :
- Apprentissage par renforcement positif. Ce type d’apprentissage par renforcement implique l’envoi d’un feedback positif ou d’une récompense après que l'agent a eu un bon comportement, ce qui l’encourage à le reproduire à l’avenir.
- Apprentissage par renforcement négatif. Ce type de renforcement consiste à supprimer une condition négative afin d’augmenter les chances qu’un comportement particulier se reproduise, ou à renforcer un comportement particulier qui permettra d’éviter un résultat négatif.
Applications du machine learning
De nombreux secteurs d'activité qui manipulent de grands volumes de données reconnaissent la valeur du machine learning pour accroître leur productivité. Le machine learning ne se substitue pas à l'humain. Il s’agit d’un outil qui permet d'extraire des informations rapidement et avec précision, afin que les humains puissent évaluer les actions recommandées et prendre de meilleures décisions, plus rapidement.
Voici quelques-uns des secteurs d’activité qui font le plus appel au machine learning.
Santé.
Le machine learning est en plein essor dans le domaine de la santé. Les capteurs et appareils portables, comme les montres intelligentes ou les appareils de suivi d'activité, peuvent aider les spécialistes de la santé à obtenir des informations en temps réel sur la santé d'une personne malade. Les avantages du machine learning dans le domaine de la santé incluent :
- Analyse plus rapide et plus efficace des données. Avec les données présentées et analysées en temps réel, les signaux d’alerte ou les tendances de santé peuvent être repérés facilement afin de poser un diagnostic ou de prescrire des traitements plus rapidement.
- Évaluation de la santé de la patientèle en temps réel pour des soins plus personnalisés. Si les médicaments traitent les symptômes, les effets secondaires peuvent être différents selon les malades. Le machine learning peut étudier les gènes des malades afin de leur fournir des soins personnalisés et des traitements ciblés.
- Accélération de la découverte de nouveaux médicaments. Avec le machine learning, le processus de création d’un nouveau médicament, long et coûteux, peut être accéléré. Certains outils de machine learning sont capables d’analyser de grands jeux de données pour contribuer à la découverte de nouvelles options thérapeutiques potentielles.
Finance.
Les banques et autres établissements financiers gèrent de grandes quantités d’informations sensibles, et sont nombreux à avoir opté pour l’utilisation des technologies de machine learning afin d’offrir un service plus sécurisé et plus performant à leur clientèle. Voici certains avantages du machine learning dans le secteur financier :
- Nouveaux insights sur les données. De nouvelles opportunités d'investissement peuvent être découvertes rapidement et l’obtention de meilleurs insights permet, par exemple, de savoir quand effectuer une transaction.
- Meilleure protection contre les fraudes. La sécurité est cruciale dans la gestion des informations financières. L'exploration des données permet de repérer les utilisateurs et les utilisatrices à haut risque et aide les systèmes de cybersurveillance à identifier les activités potentiellement frauduleuses.
Retail.
Le secteur du retail utilise le machine learning pour proposer des expériences personnalisées à chaque personne et fournir une assistance supplémentaire à la clientèle. Le machine learning offre aux retailers la possibilité d'élargir leur clientèle tout en réduisant leurs coûts. Voici quelques avantages clés :
- Expériences d'achat personnalisées. De nombreux sites de retail en ligne utilisent le machine learning pour proposer des suggestions de produits basées sur les achats récents ou les signets. Sur un site e-commerce, les robots peuvent être chargés de répondre aux questions immédiates de la clientèle, ce qui libère du temps au personnel humain.
- Amélioration du marketing. Le machine learning peut être utile pour planifier le merchandising client, élaborer des campagnes publicitaires, optimiser les prix et obtenir des informations sur la clientèle.
Algorithmes de machine learning
Le machine learning peut être utilisé pour créer des moteurs et des algorithmes de recommandation afin de personnaliser les produits et services pour chaque membre de la clientèle.
Des sociétés comme YouTube et Netflix s’appuient sur ces algorithmes pour recommander des films et des émissions aux audiences en fonction de leur historique de visionnage. Les sites marchands et autres sites web peuvent suggérer des produits et des services en fonction des articles enregistrés ou achetés. De plus, les réseaux sociaux font appel au machine learning pour faire des recommandations, avec des publications différentes qui apparaissent sur le fil d’actualité de chaque personne en fonction des publications qu’elle a appréciées ou des comptes auxquels elle s’est abonnée.
La personnalisation des expériences client et l’obtention d’informations supplémentaires aident les entreprises à mieux servir leur clientèle. Toutefois, les technologies de machine learning s’accompagnent de nombreux défis.
Défis du machine learning.
Même si le machine learning a boosté l'efficacité de nombreuses entreprises dans divers secteurs, il présente certains inconvénients comme n'importe quelle nouvelle technologie. Cette technologie soulève, en particulier, des questions éthiques et de coût.
-
Biais et discrimination.
Malheureusement, les données utilisées pour entraîner les modèles de machine learning sont susceptibles de refléter des biais humains. Les algorithmes qui apprennent à partir de jeux de données contenant des erreurs ou excluant certaines populations créent des représentations inexactes du monde. Ces erreurs ne permettent pas de refléter fidèlement la réalité qui nous entoure et peuvent également être discriminatoires. La plupart des entreprises font preuve de diligence raisonnable pour éliminer les biais potentiels dans leurs démarches d'automatisation. Néanmoins, l'utilisation de l'intelligence artificielle peut entraîner certaines conséquences.
Par exemple, Amazon a utilisé l’automatisation pour simplifier l’embauche et a involontairement discriminé des personnes candidates aux postes techniques en fonction de leur genre. L’entreprise a ensuite supprimé le processus. Recueillir des avis et des données auprès de personnes issues de milieux divers contribue à réduire les biais et la discrimination.
-
Confidentialité
Le machine learning exige des données, ce qui soulève des préoccupations en matière de confidentialité. Lorsqu’on gère tous types de données, en particulier les informations à caractère personnel (PII), leur confidentialité et leur sécurité sont d’une importance capitale. Dans le monde, de plus en plus de législations visant à protéger les données personnelles sont adoptées.
Le Règlement général sur la protection des données (RGPD) est un règlement de l'Union européenne adopté en 2016 pour protéger les données personnelles des personnes au sein de l'Union européenne et de l'Espace économique européen et pour garantir à chaque personne un meilleur contrôle sur ses informations. Aux États-Unis, la Californie a adopté le California Consumer Privacy Act (CCPA) en 2018 pour obliger les entreprises à informer les consommateurs et les consommatrices lorsque leurs données sont collectées.
-
Coût
L‘intégration du machine learning dans les processus métier peut s’avérer coûteuse. Les spécialistes en science des données, les personnes qui pilotent généralement ces projets, exigent souvent des salaires élevés. L’infrastructure logicielle associée à l’intégration de pratiques de machine learning peut également s’avérer onéreuse.
Le machine learning est mis en œuvre pour analyser de grands jeux de données créés au fil du temps, et de nombreuses ressources sont nécessaires pour faire de cette technologie un élément utile à la stratégie d’entreprise. Pour nombre d’entreprises, le temps et les ressources investis en valent largement la peine, mais il ne faut pas oublier que le machine learning est un réel investissement et que le système peut devenir de plus en plus complexe et coûteux à mesure qu’il se développe.
Proposez des expériences client exceptionnelles avec le machine learning.
Besoin d'améliorer la segmentation et la personnalisation avec le machine learning ? Découvrez comment Adobe Real-Time CDP peut vous aider.
Recommandé pour vous
https://business.adobe.com/fragments/resources/cards/thank-you-collections/rtcdp
