
Ein Data Lake ist ein zentrales Repository zum Speichern großer Mengen von strukturierten, teilstrukturierten und unstrukturierten Daten in ihrer Rohform ohne ein vordefiniertes Schema. Data Lakes ermöglichen die flexible Datenaufnahme aus verschiedenen Quellen und unterstützen Analysen, Visualisierung und maschinelles Lernen, die wertvolle Erkenntnisse liefern.
Was ist ein Data Lake?
Ein Data Lake ist ein Repository, in dem ihr sowohl unstrukturierte als auch strukturierte Daten speichern könnt. Data Lakes erlauben das Speichern großer Mengen von strukturierten, teilstrukturierten und unstrukturierten Daten – in ihrem nativen Format und in beliebigem Umfang.
Der Zweck eines Data Lake ist es, Rohdaten in ihrer ursprünglichen Form aufzubewahren, ohne dass vordefinierte Schemata oder Strukturen benötigt werden. Das heißt, dass Daten aus verschiedensten Quellen erfasst und auf besonders flexible und kosteneffiziente Weise gespeichert werden können.
Funktionsweise von Data Lakes.
Data Lakes erfassen und speichern Rohdaten in ihrem Originalformat. Der Prozess beginnt meist mit der Datenaufnahme aus mehreren Quellen, z. B. Geräten im Internet der Dinge, Social-Media-Feeds, Unternehmenssystemen und Datenbanken. Anschließend werden diese Daten in einer skalierbaren Speicherlösung gespeichert, oft auf Cloud-basierten Plattformen.
Im Gegensatz zu einem Data Warehouse verbleiben die Daten in einem Data Lake in ihrem unstrukturierten Rohformat, bis sie benötigt werden. Benutzende können diese Daten verarbeiten, abfragen und in strukturierte Formate transformieren, um verschiedene Analysen, Reports oder Visualisierungen zu erstellen. Dank der enormen Mengen an Rohdaten unterstützen Data Lakes auch erweiterte Funktionen wie maschinelles Lernen und künstliche Intelligenz.
Gründe für einen Data Lake.
Unternehmen aus allen Branchen nutzen Daten zur Unterstützung ihrer Entscheidungsfindungsprozesse und zur Wahrnehmung von Wachstumschancen. Dies wird durch einen Data Lake möglich, denn er stellt Unternehmen einen zuverlässigen Ort bereit, an dem sie enorme Datenmengen speichern, verwalten und analysieren können.
- Verarbeitung von Big Data. Data Lakes speichern riesige Datensätze im Tera- oder Petabyte-Bereich, sodass Unternehmen große Volumen von strukturierten, teilstrukturierten und unstrukturierten Daten verarbeiten können. Sie unterstützen verteilte Computing-Frameworks für skalierbare Datenverarbeitung und erweiterte Analysen. Diese Merkmale sind für den Umgang mit Big Data im benötigten Umfang notwendig.
- Verwaltung unstrukturierter Daten. Data Lakes können unstrukturierte Daten wie Videos, Audio, Bilder sowie Text effizient speichern und erlauben die Analyse von Rohdaten. Dies ist insbesondere für Medienunternehmen, im Gesundheitswesen sowie für Social Media nützlich, weil damit erweiterte Analysen wie Sentiment-Analysen und Bilderkennung für nicht-tabellarische Daten möglich sind.
- Echtzeitanalysen. Data Lakes können mit Tools wie Adobe Analytics für Echtzeitanalysen integriert werden, sodass Unternehmen Live-Daten überwachen und sofort Entscheidungen treffen können. Dies ist insbesondere in Branchen wie E-Commerce, Finanzdienstleistungen und Fertigung wichtig, da hier umgehende Erkenntnisse und schnelle Entscheidungen unverzichtbar sind.
Laut einer Untersuchung von 2024 wird der weltweite Data-Lake-Markt bis zum Jahr 2030 Schätzungen zufolge 45,8 Milliarden US-Dollar erreichen. In einer Umfrage unter IT-Fachleuten aus dem Jahr 2021 erklärten 69 %, dass ihr Unternehmen bereits einen Data Lake implementiert hat. Es ist davon auszugehen, dass diese Zahl inzwischen weiter gestiegen ist.
Wann braucht ihr einen Data Lake?
- Verarbeitung von Big Data. Wenn ihr über große Mengen an Daten verfügt, die verarbeitet und analysiert werden müssen, kann ein Data Lake eine skalierbare und kosteneffektive Lösung darstellen.
- Unstrukturierte Daten. Wenn euer Unternehmen mit unstrukturierten Daten wie Video-, Audio-, Bild- und Textdateien arbeitet, kann ein Data Lake die perfekte Lösung sein. Data Lakes können Daten in ihrer Rohform speichern, sodass ihr unterschiedliche Analysen und KI-Modelle ausführen könnt, um Erkenntnisse zu gewinnen.
- Datenverarbeitung in Echtzeit. Wenn ihr Daten in Echtzeit verarbeiten müsst, kann euch ein Data Lake dabei unterstützen, Daten schnell zu erfassen und echtzeitbasierte Analyse-Dashboards zu erstellen.
- Kosteneffektive Speicherung. Data Lakes können eine kosteneffektive Methode zum Speichern großer Datenmengen darstellen. Weil die Daten in ihrer Rohform gespeichert werden, müsst ihr keine Zeit oder Ressourcen für das Strukturieren bzw. Bereinigen aufwenden, bevor ihr sie speichert.
- Zusammenarbeit: Mit Data können Daten aus verschiedenen Abteilungen zentralisiert werden, sodass Teams leichter zusammenarbeiten und Daten gemeinsam verwenden können. Unterschiedliche Entscheidungstragende, einschließlich Fachkräften für Datenanalysen, Datenwissenschaftlerinnen und -wissenschaftlern sowie Business-Fachleuten, können auf die Daten zugreifen, um Analysen durchzuführen und datengestützte Entscheidungen zu treffen.
Data Lake und Data Warehouse im Vergleich.
Der wichtigste Aspekt ist die Tatsache, dass ein Data Lake Daten aufnimmt und erst später aufbereitet. Bei einem Data Warehouse dagegen hat die Organisation und Struktur der Daten oberste Priorität, wie es in einem physischen Lagerhaus oder Vertriebszentrum der Fall ist.
Stellt euch die Funktion und den Prozess eines Data Lakes so vor, als würde Regen in einen See fallen. Alle Tropfen, die auf die Oberfläche des Sees fallen, werden vom Gewässer aufgenommen. Und dasselbe Grundprinzip gilt auch für einen Data Lake.
Ein echtes Lagerhaus würde dagegen niemals ein Bündel unsortierter und unverpackter Produkte oder eine nicht angekündigte Lieferung akzeptieren, und genauso wenig kann ein Data Warehouse neue Informationen aufnehmen, wenn sie nicht zuvor aufbereitet und strukturiert wurden.
Wann solltet ihr einen Data Lake oder ein Data Warehouse wählen?
Allgemein gesagt solltet ihr einen Data Lake verwenden, wenn euer Unternehmen große Datenvolumen aus vielen verschiedenen Quellen sammeln muss, die Daten aber nicht von Anfang an strukturiert sein müssen.
Unternehmen, die allgemeine Verbraucherdaten erfassen, würden wahrscheinlich mithilfe eines Data Lake folgende Fragen klären:
- Wie sind Käuferinnen und Käufer auf die Website des Unternehmens gelangt?
- Wo wohnt die Kundschaft des Unternehmens?
- Wie ist der Kundenstamm demografisch aufgebaut?
Dagegen würde ein Vertrieb, der eine zentrale Datenquelle für sein Bestands-Management braucht, eher ein Data Warehouse benötigen. Sämtliche strukturierten Daten, die in das Data Warehouse geladen werden, liefern sofort Echtzeit-Erkenntnisse zum Lagerbestand, zur Lagerkapazität und anderen Metriken des Vertriebs.
Angesichts der individuellen Anwendungsszenarien der beiden Lösungen ist es wahrscheinlich, dass euer Unternehmen sowohl einen Data Lake als auch ein Data Warehouse braucht.
Data Lakehouse: das Beste aus beiden Welten.
Das Data-Lakehouse-Modell verbindet die Stärken von Data Lakes und Data Warehouses. Damit erhaltet ihr die Kosteneffizienz und Flexibilität eines Data Lake, sodass ihr enorme Volumen an unstrukturierten Rohdaten (z. B. Protokolle, Videos und Social-Media-Content) ohne vordefinierte Schemata speichern könnt. Dies ist die ideale Lösung für Unternehmen, die mit großen Datenmengen arbeiten.
Gleichzeitig besitzen Data Lakehouses die Funktionen von Data Warehouses zur Nutzung strukturierter Daten, sodass sich damit Analysen und Business-Intelligence-Aufgaben durchführen lassen. Damit können Unternehmen sowohl strukturierte als auch unstrukturierte Daten für SQL-Abfragen und ML-Modelle (maschinelles Lernen) verarbeiten und wertvolle Erkenntnisse gewinnen.
Durch das einheitliche Daten-Management reduzieren Data Lakehouses eure Datensilos und verbessern die Datenverfügbarkeit. Sie eignen sich auch sehr gut für KI und unterstützen datenwissenschaftliche Auswertungen und ML-Programme. Durch die Nutzung von Open-Source-Technologien wie Apache Spark oder Delta Lake stellen Data Lakehouses eine skalierbare und moderne Lösung dar. Dieser einheitliche Ansatz verbessert die Effizienz, liefert schneller Erkenntnisse und senkt die Gesamtkosten für Unternehmen.
Studien von 2022 haben gezeigt, dass 66 % der befragten Unternehmen ein Data Lakehouse nutzen. Gleichzeitig gab die Hälfte davon an, dass sie dies hauptsächlich aufgrund der verbesserten Datenqualität tut.
Data-Lake-Architektur.
Ein Data Lake kann auf verschiedene Arten erstellt werden. Das Architektur-Framework und der Aufbau sollten aber an die individuellen Anforderungen eures Unternehmens angepasst werden.
Die drei wichtigsten Data-Lake-Architekturen.
1. Hadoop.
Apache Hadoop ist ein Open-Source-Tool für die Verwaltung und Verarbeitung umfangreicher Daten auf mehreren Servern.
2. Amazon WorkSpaces.
Amazon WorkSpaces stellt End-to-End-Cloud-Computing-Services für Unternehmen jeder Größe bereit.
3. Microsoft Azure.
Microsoft Azure dient als Infrastruktur mit integrierten Analyseprozessen und Berechnungsfunktionen.
Die drei wichtigsten Data-Lake-Architekturprinzipien.
1. Es werden keine Daten abgewiesen.
Die erste Regel beim Aufbau eines Data Lakes ist zugleich die wichtigste: Weist niemals Daten ab, auch wenn ihr momentan keine Verwendung dafür habt. Sammelt so viele Informationen wie irgend möglich, fügt sie eurem Data Lake hinzu und hebt euch die Gedanken über deren Verwendung für später auf.
2. Belasst Daten im ursprünglichen Zustand.
Bei der Data-Lake-Methode stehen Effizienz und Skalierbarkeit an vorderster Stelle. Deshalb ist es unabdingbar, dass ihr während der Erfassung alle Daten im Originalzustand belasst. Anderenfalls verspielt ihr die Effizienzvorteile dieser Strategie.
3. Daten können später an die Analyseanforderungen angepasst werden.
Wenn ihr eure Technologien für Business Intelligence, maschinelles Lernen und KI unterstützen möchtet, benötigt ihr Daten – und zwar jede Menge. Zum Zeitpunkt der Erfassung müsst ihr euch dabei keine Gedanken über die Anforderungen eines konkreten Datensatzes machen. Ihr könnt Daten erfassen und speichern, ohne einen konkreten Zweck dafür zu haben oder eine Schemadefinition zu besitzen. Ihr könnt den Datensatz später jederzeit transformieren, damit er optimal für eure Analysen geeignet ist.
Ebenen der Data-Lake-Struktur.
Die Ebenen der Data-Lake-Struktur sind die unterschiedlichen Phasen der Organisation und Verwaltung von Daten innerhalb einer Data-Lake-Architektur, beginnend mit der Datenaufnahme.
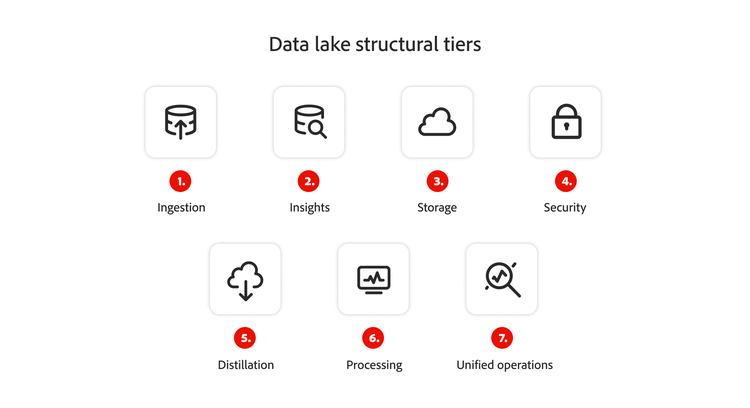
- Aufnahme. Die Ebene der Datenaufnahme liegt wahrscheinlich ganz links in eurem Workflow. Daten können in Echtzeit geladen oder in Paketen übertragen werden.
- Erkenntnisse. Die Ebene der Erkenntnisse befindet sich auf der rechten Seite und gibt an, welche umsetzbaren Informationen aus eurem Data Lake abgeleitet werden können.
- Speicherung. Der Speicher ist nicht zwingend eine Ebene der eigentlichen Data-Lake-Architektur. Er soll den Ort darstellen, an dem eure Informationen aufbewahrt werden, wenn sie nicht in Verwendung sind. Dies könnte beispielsweise ein Cloudserver sein.
- Sicherheit. Die Sicherheit in der Data-Lake-Architektur ist mit allen anderen Ebenen verwoben, da ihr für die Wahrung der Integrität der von euch erfassten Informationen verantwortlich seid.
- Destillation. Bei der Destillation werden die Informationen aus dem Speicher entonommen und in strukturierte Daten transformiert.
- Verarbeitung. Auf der Verarbeitungsebene wendet euer Analyse-Team die Algorithmen auf eure Daten an, um sie für die Analyse vorzubereiten.
- Unified Operations. Die Ebene der Unified Operations fungiert als Governance- und Auditing-Workflow, damit ihr die Daten-Management-Prozesse überwachen und optimieren könnt.
Alle genannten Ebenen sind essenziell für die Funktion und Leistung eures Data Lakes. Jede Ineffizienz oder suboptimale Leistung an einem einzigen Touchpoint kann eure Datenanalysen beeinträchtigen und euch daran hindern, alle Informationen optimal zu nutzen.
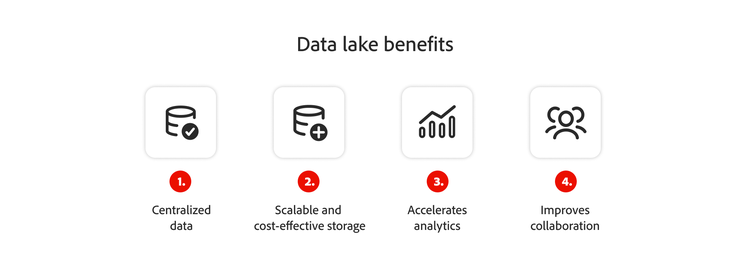
Vorteile von Data Lakes.
-
Zentralisierte Daten. Wenn Daten in unzusammenhängenden Plattformen und Programmen gespeichert sind, kann dies zu Datensilos führen. Durch die Aggregation der Daten in einem Data Lake werden Silos beseitigt, da alle wichtigen Unternehmensinformationen an einem zentralen Speicherort zur Verfügung stehen.
Amazon zentralisiert Kundendaten, das Inventar sowie Vertriebsmetriken in einem Data Lake, sodass Teams an einem Ort die Präferenzen erfassen, Lieferketten verwalten und die Preisgestaltung optimieren können, sodass Datensilos vermieden werden.
-
Skalierbare und kosteneffektive Speicherung. Um wachsen zu können, benötigen Unternehmen Daten – und zwar jede Menge. Ohne einen Data Lake müssen Unternehmen die Daten bereits während der Aufnahme strukturieren, wodurch sie möglicherweise davor zurückschrecken, Daten in den Mengen zu erfassen, wie sie für ihre Analysen notwendig sind. Data Lakes beseitigen diese Hürde, da Unternehmen damit Daten in jedem beliebigen Format speichern können.
Netflix sammelt riesige Mengen an Daten zu Benutzenden, Sehgewohnheiten sowie Streaming-Verhalten in einem Data Lake. Damit lassen sich Rohdaten kosteneffizient sowie skalierbar speichern, was personalisierte Empfehlungen und die Erstellung von Content ermöglicht.
-
Schnellere Analysen. Data Lakes sind essenziell für Datenanalysen. Dank dieser riesigen Informations-Pools können Unternehmen mit modernen Analyse-Prozessen in Echtzeit auf Marketing-Erkenntnisse zugreifen und ihre Entscheidungsfindung optimieren.
Tesla erfasst in Echtzeit Daten von den eigenen Fahrzeugen in einem Data Lake. Damit will das Unternehmen die Leistung verbessern, die Funktionen des Autopiloten erweitern sowie die Akkunutzung analysieren. Dies ermöglicht Innovationen und erlaubt prädiktive Wartung.
-
Verbesserung der Zusammenarbeit. Durch die Konsolidierung von Daten aus verschiedenen Quellen in einem zentralen Repository ist der Zugriff aus dem gesamten Unternehmen möglich. Data Lakes beseitigen Hindernisse zwischen isolierten Systemen und verbessern die abteilungsübergreifende Zusammenarbeit.
Coca-Cola aggregiert Informationen zu Vertrieb, Kunden-Feedback sowie Social-Media-Interaktionen in einem Data Lake. Dadurch wird die Zusammenarbeit zwischen den Abteilungen für Marketing, Vertrieb sowie Forschung und Entwicklung gefördert, die Produktentwicklung beschleunigt und das regionale Marketing unterstützt.
Außerdem sorgen Data Lakes im gesamten Unternehmen für eine bessere Transparenz von Informationen. Da die Daten vor der Speicherung in Data Lakes nicht strukturiert werden müssen, beschleunigen sie auch die Prozesse zur Datenerfassung und ermöglichen es eurem Unternehmen, mehr Informationen über eure Kundschaft und euren Markt zu sammeln.
Herausforderungen bei Data Lakes.
- Sicherheit. Je mehr Daten ihr sammelt, desto schwieriger kann es sein, sie zu verwalten, zu klassifizieren und zu schützen. Außerdem geratet ihr ins Visier von Hackerinnen und Hackern, die stets versuchen, an wertvolle Kundeninformationen zu gelangen.
- Datenqualität. Ohne angemessene Kontrolle der Datenqualität können sich Data Lakes mit minderwertigen oder irrelevanten Daten anfüllen, die sich nur schwer verwalten und analysieren lassen.
- Technologie-Überflutung. Data Lakes können Daten wesentlich schneller aufnehmen als Data Warehouses. Aber wenn ihr oder eure technischen Fachkräfte nicht Schritt halten könnt, kann dies zu Überlastung und Leistungseinbußen führen.
- Data Governance. Je nach Branche müsst ihr vielleicht strenge Data-Governance-Protokolle befolgen, um Konformität zu gewährleisten und Bußgelder zu vermeiden. Dies ist bei einem prall gefüllten Data Lake nicht immer einfach.
- Datenintegration. Ohne angemessene Integration kann es dazu kommen, dass Daten schlecht organisiert sind. Das macht das Auffinden, Abfragen und Analysieren der Daten schwieriger.
- Daten-Management. Data Lakes erfordern effektive Strategien für das Daten-Management, damit Daten richtig organisiert, gekennzeichnet und markiert werden und sich leicht suchen, abrufen und analysieren lassen.
Wenn ihr euch aber im Vorfeld einer Investition in eine Data-Lake-Architektur mit diesen Herausforderungen beschäftigt, könnt ihr diese Probleme umgehen und das Optimum aus eurem Daten-Management-Tool herausholen.
Die Wahl der richtigen Plattform zur Erstellung des Data Lakes in eurem Unternehmen.
Data Lakes sind eine skalierbare und flexible Lösung zum Vereinheitlichen und Analysieren riesiger Datenmengen, wie sie für erweiterte Analysen und KI-Programme erforderlich sind.
Bei der Wahl der für euer Unternehmen richtigen Data-Lake-Lösung solltet ihr folgende Faktoren berücksichtigen:
- Skalierbarkeit. Kann die Plattform mit dem Wachstum eures Unternehmens Schritt halten?
- Integration. Kann sie mit vorhandenen Systemen und Analyse-Tools zusammenarbeiten?
- Kosteneffizienz. Wie hoch sind die Anfangs- und Betriebskosten?
- Sicherheit. Bietet die Lösung integrierte Verschlüsselung und Zugriffskontrollen?
Wenn ihr selbst erleben möchtet, wie euer Unternehmen mit Adobe Experience Platform einen Data Lake optimal nutzen kann, fordert eine Demo an.
Unsere Empfehlungen für euch.
https://business.adobe.com/fragments/resources/cards/thank-you-collections/generic
