
データレイクとは、構造化データ、半構造化データ、非構造化データなどの大量のデータを、スキーマを定義することなく、そのままの形式で一元的に保存できるリポジトリのことです。様々なソースからの柔軟なデータ取り込みを可能にし、分析、ビジュアライゼーション、マシンラーニングをサポートして、貴重なインサイトを提供します。
データレイクとは
データレイクとは、構造化データと非構造化データの両方を保存できるレポジトリです。データレイクとは、構造化データ、半構造化データ、非構造化データなどの大量のデータを、規模を問わず、ネイティブ形式で保存できるデータリポジトリのことです。
データレイクの目的は、スキーマや構造をあらかじめ定義することなく、生のデータをそのままの形で保存することです。つまり、様々なソースからデータを取り込み、より柔軟で費用対効果の高い方法で保存できます。
データレイクの仕組み
データレイクは、生のデータを元の形式のまま取り込み、格納します。このプロセスは通常、IoTデバイス、ソーシャルメディアのフィード、エンタープライズシステム、データベースなど、複数のソースからのデータ取り込みから始まりますこのデータは、拡張性のあるストレージソリューション(通常はクラウドベースのプラットフォーム上)に格納されます
データウェアハウスとは異なり、データレイク内のデータは、必要になるまで生のままの構造化されていない形式で保持されます。ユーザーは、その時点でデータを処理、クエリ、構造化された形式に変換して、様々なタイプの分析、レポート、ビジュアライゼーションに使用できます。データレイクは、これらのアプリケーションを動かすための膨大な生データのプールを提供することで、マシンラーニングや人工知能などの高度な機能もサポートしています。
データレイクが必要な理由
あらゆる業界で、多くの企業は、データを活用して意思決定プロセスを促進し、ビジネス成長の機会を獲得しています。データレイクを活用することで、企業は膨大なデータを安全に保存、管理、分析できるようになります。
- ビッグデータ処理:データレイクは、テラバイトからペタバイト規模の膨大なデータセットを処理し、大量の構造化データ、半構造化データ、非構造化データの処理を可能にします。また、分散コンピューティングフレームワークをサポートし、拡張可能なデータ処理と高度な分析を容易にします。これらは、大規模なビッグデータを処理するために不可欠です。
- 非構造化データの処理:データレイクは、ビデオ、オーディオ、画像、テキストなどの非構造化データを効率的に保存するため、企業は生のコンテンツの分析が可能になります。特に、メディア、ヘルスケア、ソーシャルメディアなどの業界で有用であり、非表形式のデータに対して好感度分析や画像認識などの高度な分析を行うことができます。
- リアルタイム分析:データレイクは、Adobe Analysisなどのツールと統合することでリアルタイム分析を可能にし、企業はライブデータをモニタリングして即座に意思決定を行うことができます。これは、タイムリーなインサイトと迅速な意思決定が不可欠なeコマース、金融、製造などの業界にとって非常に重要です。
2024年に発表された調査によると、2030年までにデータレイクのグローバル市場は458億米ドルに達すると予測されています。2021年にIT専門家を対象に行った調査では、69%が自社でデータレイクを既に導入していると回答しており、その数はさらに増加している可能性があります。
データレイクの活用例
- ビッグデータ処理:大量のデータを処理および分析する必要がある場合、データレイクはスケーラブルで費用対効果の高いソリューションを提供します
- 非構造化データ:動画、音声、画像、テキストなどの非構造化データを扱う企業では、データレイクが理想的なソリューションとなります。データを生のまま保存できるため、様々な分析やAIモデルを適用してインサイトを抽出できます。
- リアルタイムのデータ処理:リアルタイムでデータを処理する必要がある場合、データレイクはデータを迅速に収集、処理し、リアルタイムの分析ダッシュボードを構築するのに役立ちます。
- 費用対効果の高いストレージ:データレイクは、大量のデータを保存するための費用対効果の高い方法です。データは生の状態で保存されるため、保存前にデータの構造化やクリーニングに時間やリソースを費やす必要がありません。
- コラボレーション:また、データレイクは企業の様々な部門のデータを一元管理するためにも利用できるので、部門間でのコラボレーションやデータの共有が容易になります。データアナリスト、データサイエンティスト、ビジネスリーダーなど、様々な関係者がデータにアクセスでき、各自が分析を実行し、データにもとづいた意思決定を行うことができます。
データレイクかデータウェアハウスか
データレイクは、データを収集し、後で使用するために準備を整えることを目的としています。一方、データウェアハウスは、物理的な倉庫や流通センターと同様に、組織と構造に焦点を当てます。
データレイクの機能とプロセスを、湖に降る雨に例えて説明しましょう。湖面に落ちた雨滴は、水中に蓄積されます。データレイクも同様に、データが長期にわたって蓄積されます。
一方、実際の倉庫では、未梱包の製品や予定外の出荷を受け付けません。データウェアハウスも同様に、準備が整っていないデータや、構造化されていないデータを受け取ることはできません。
データレイクまたはデータウェアハウスをどのような場合に利用するべきか
一般的に、様々なソースから膨大なデータを収集する必要があるものの、それらのデータをすぐに構造化する必要がない場合は、データレイクを使用することをお勧めします。
たとえば、一般的な消費者データを収集する企業は、データレイクを使用して次のようなことを把握します。
- 購入者が自社のwebサイトを発見した方法
- 顧客の居住地
- 顧客基盤のデモグラフィック情報
一方、在庫を管理するための信頼できる唯一の情報源が必要なディストリビューターは、データウェアハウスを導入する必要があるでしょう。データウェアハウスに格納された構造化データは、在庫やストレージ容量などの指標に関するリアルタイムのインサイトを提供します。
それぞれ固有のユースケースを考慮すると、データレイクとデータウェアハウスの両方を導入する必要があることに気付くでしょう。
データレイクハウス:両方の長所を融合した理想のソリューション
データレイクハウスモデルは、データレイクとデータウェアハウスの両方の長所を組み合わせたモデルです。データレイクのコスト効率と柔軟性を備え、事前定義されたスキーマなしで大量の未構造化データ(ログ、ビデオ、ソーシャルメディアコンテンツなど)を格納できるため、大量のデータを持つ組織に最適です。
同時に、データレイクハウスはデータウェアハウスの構造化データ機能も組み込んでいるため、分析やビジネスインテリジェンス(BI)タスクも実行できます。これにより、企業は構造化データと非構造化データの両方を処理しながら、SQLのようなクエリやマシンラーニングモデルを実行して、貴重なインサイトを得ることができます。
データレイクハウスは、統合されたデータ管理を提供し、分断化を解消してデータのアクセス性を向上させます。また、AIとの互換性も高く、データサイエンスやマシンラーニングアプリケーションをサポートしています。データレイクハウスは、Apache SparkやDelta Lakeなどのオープンソーステクノロジーを使用して、スケーラブルで最新のソリューションを提供します。 この統合アプローチにより、効率が向上し、インサイトの獲得を促進し、組織の全体的なコストが削減されます。
2022年の調査によると、企業の66%がデータレイクハウスを導入しており、半数がデータ品質の向上を主な導入理由として挙げています。
データレイクのアーキテクチャ
データレイクを構築する方法はいくつかありますが、自社独自のニーズに合わせて、データレイクのアーキテクチャフレームワークと構造を設計する必要があります。
3つの主要なアーキテクチャ
1. Hadoop
Apache Hadoopは、複数のサーバーをまたぐ大規模データの管理と処理を支援するオープンソースのツールです。
2. Amazon WorkSpaces
Amazon WorkSpacesは、規模を問わず、あらゆる企業にエンドツーエンドのクラウドコンピューティングサービスを提供します。
3. Microsoft Azure
Microsoft Azureは、分析プロセスとコンピューティング機能をサポートする統合インフラとして機能します。
データレイクアーキテクチャの3つの主要な原則
1. データを拒否しない
データレイクを形成する際の最初のルールであり、最も重要なルールです。現在使用する予定があるかどうかに関わらず、データを拒否しないこと。可能な限り多くのデータを収集し、後で処理する方法を決定しましょう。
2. データを現状のまま保持
データレイクでは、効率性と拡張性を重視するため、収集段階ではデータを現状のまま保持することが重要です。そうしなければ、データレイクの効率性が失われてしまいます。
3. 分析ニーズに応じてデータを変換
ビジネスインテリジェンス、マシンラーニング、AIテクノロジーを活用するには、膨大なデータが必要です。ただし、データセットの収集時にその特定の要件を明確に定義する必要はありません。当初から特定の目的やスキーマ定義を定めずに、データを収集、保存できます。後で分析ニーズに応じてデータを変換できます。
データレイクの構造層
データレイクの構造階層とは、データレイクアーキテクチャにおける、データ取り込みから始まるデータ整理および管理の様々な段階のことです。
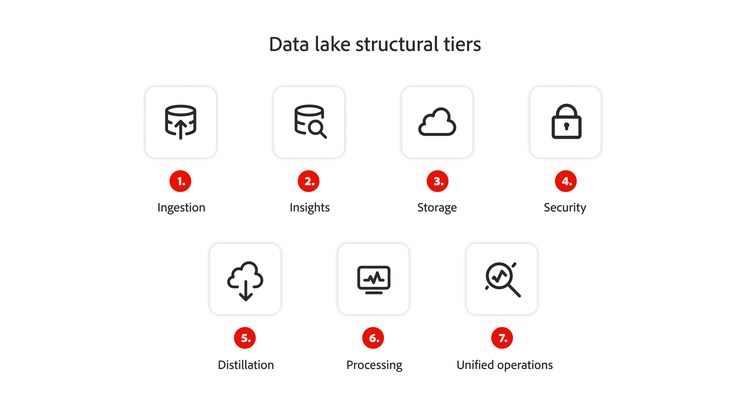
- 取り込み:取り込み層は、ワークフローの左側に表示されます。データはリアルタイムでロードされるか、一括送信されます。
- インサイト:インサイト層は右側にあり、データレイクに格納されている実践的なデータを提示します。
- ストレージ:ストレージは必ずしもデータレイクアーキテクチャの階層の一つではありませんが、使用されていない情報がどこに格納されているか(例、クラウドサーバー上など)を把握しておく必要があります。
- セキュリティ:セキュリティは、あらゆるアーキテクチャ層に組み込まれており、収集したデータの完全性を維持します。
- 蒸留:蒸留層では、ストレージから情報を取り出し、構造化データに変換します。
- 処理:分析チームがアルゴリズムを実行し、分析に向けてデータを準備するフェーズです。
- 統合オペレーション:ガバナンスおよび監査ワークフローとして機能し、データ管理プロセスを監視および最適化できます。
これらの層はすべて、データレイクの機能とパフォーマンスに大きな影響を与えます。単一の接点における効率性やパフォーマンスの低下は、データ分析プロセスを妨げ、データの価値を最大化できなくなる恐れがあります。
データウェアハウスの利点
-
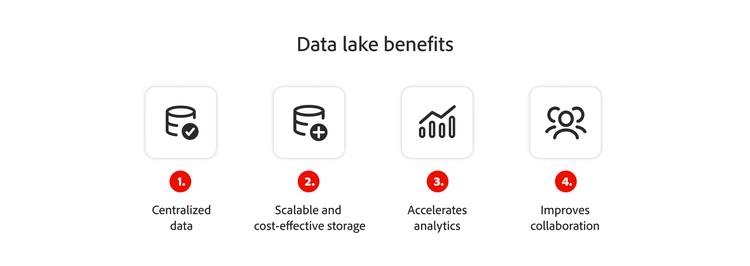
データの一元化:データがプラットフォームやアプリケーションごとに格納されていると、分断するリスクが高まります。データレイクにデータを統合することで、すべての重要なビジネス情報が一元管理された場所からアクセス可能になり、分断化の解消に役立ちます。
Amazonは、顧客データ、在庫、販売指標をデータレイクに一元化することで、各部門が1つの場所で顧客の好みを追跡し、サプライチェーンを管理し、価格設定を最適化できるようになり、データの分断化を解消しています。
-
スケーラブルで費用効果の高いストレージ:ビジネスを成長させるためには、膨大なデータが必要です。データレイクがない場合、データを構造化する必要があります。しかしこれは、十分なデータを収集および分析することを妨げる可能性があります。データレイクを導入すれば、任意の形式でデータを保存できるようになります。
Netflixは、膨大なユーザーデータ、視聴習慣、ストリーミング行動などをデータレイクに保存して、生データのスケーラブルで費用効果の高いストレージを実現することで、パーソナライズされたおすすめやコンテンツ制作を推進しています。
-
分析の迅速化:データレイクは、データ分析に不可欠です。大規模なデータレイクを活用することで、企業は最新の分析プロセスを利用して、リアルタイムの市場インサイトにアクセスし、意思決定の指針とすることができます。
Teslaは、電気自動車からリアルタイムで収集したデータをデータレイクに蓄積し、車両性能の向上、自動運転機能の強化、バッテリー使用状況の分析を通じて、イノベーションと予測メンテナンスを推進しています。
-
コラボレーションの向上:様々なソースから取得したデータを単一の一元的なリポジトリに統合することで、組織全体でのアクセスが可能になります。孤立したシステム間の障壁を取り除くことで、データレイクは部門をまたいだチーム間のコラボレーションを促進します。
Coca-Colaは、売上、顧客フィードバック、ソーシャルメディアのインサイトをデータレイクに集約し、マーケティング、セールス、R&Dなどの部門間のコラボレーションを促進して、製品開発と地域マーケティング活動を向上させています。
さらに、データレイクは、企業全体のデータ情報を詳細に可視化するのに役立ちます。データを構造化する必要がないため、データ収集プロセスを迅速化し、顧客や市場に関するより多くの情報を効率的に収集できます。
データレイクの課題
- セキュリティ:蓄積するデータが多ければ多いほど、それらのデータを管理、分類、保護することが困難になります。また、データを蓄積することは、ハッカーの標的となるリスクを高めます。攻撃者は価値のある消費者情報を入手しようと常に狙っています。
- データ品質:データ品質の管理を適切に行わないと、データレイクは低品質なデータや無関係なデータで乱雑になり、管理や分析が困難になります。
- テクノロジーの過負荷:データレイクは、データウェアハウスよりもデータを高速に取り込むことができますが、他のテクニカルリソースが不足している場合、パフォーマンスが低下する可能性があります。
- データガバナンス:一部の業界では、コンプライアンスを確保し、罰金を回避するために厳格なデータガバナンスのプロトコルを遵守する必要があるため、データレイク全体を維持することが困難になる場合があります。
- データ統合:適切に統合されていない場合、データの整理が不十分になり、データの検索、照会、分析が困難になる可能性があります。
- データ管理:データレイクには、データを適切に整理し、ラベル付けし、タグ付けして、検索、取得、分析を容易にするためには、効果的なデータ管理戦略が必要です。
データレイクアーキテクチャに投資する前に、これらの課題を把握しておくことで、適切な措置を講じ、データ管理ツールを最大限に活用できます。
データレイクを構築するための適切なプラットフォームの選択
データレイクは、膨大な量のデータを統合、分析するためのスケーラブルで柔軟なソリューションを提供し、高度な分析やAIアプリケーションの実現を可能にします。
組織向けにデータレイクソリューションを選択する際には、以下の要因を考慮するようにしてください。
- 拡張性:プラットフォームは、組織の成長に対応できるか?
- 統合既存のシステムや分析ツールと連携できるか?
- コスト効率:初期費用と運用コストは?
- セキュリティ機能:ビルトインの暗号化およびアクセス制御機能を備えているか?
Adobe Experience Platformは、データレイクを最大限に活用してビジネスを支援します。導入のご相談
